Next: 5.3.5 Dissociation Energy Up: 5.3 JUSO Setup Previous: 5.3.3 Detection Efficiency Contents
The observed peaks were asymmetric with a pronounced tail towards
lower energies. After correction for detection efficiency functions
of the following type [14,27,28] were fitted
to every peak in energy space:
| (5.12) |
| (5.13) |
the total area under ![]() equals to:
equals to:
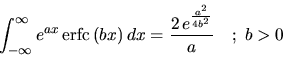 |
(5.14) |
This is used to normalize the function ![]() to an area of 1:
to an area of 1:
| (5.15) |
According to [28] the parameters ![]() and
and ![]() are
now substituted by
are
now substituted by
introducing two new constants ![]() and
and ![]() .
This choice will be justified below. The function
.
This choice will be justified below. The function
![]() may now be written as
may now be written as
where ![]() denotes the decay constant of the exponential
function in
denotes the decay constant of the exponential
function in ![]() and
and ![]() the width of the gaussian
function
the width of the gaussian
function ![]() .
.
Shifting the function
![]() along the x-axis
by
along the x-axis
by
![]() such that the mean value is equal to 0
yields:
such that the mean value is equal to 0
yields:
| (5.23) | |||
![$\displaystyle e^{a\left( x+\frac{a}{2b^{2}}-\frac{1}{a}\right) }\, \mathrm{erfc...
...a}{2b^{2}}-\frac{1}{a}\right) \right] \, \frac{a}{2\, e^{\frac{a^{2}}{4b^{2}}}}$](img223.png) |
(5.24) | ||
![$\displaystyle \frac{a}{2}e^{\frac{a^{2}}{4b^{2}}-1}e^{ax}\, \mathrm{erfc}\left[ b\left( \frac{a}{2b^{2}}-\frac{1}{a}+x\right) \right]$](img224.png) |
(5.25) |
and again substituting ![]() and
and ![]() :
:
![$\textstyle =\frac{1}{2\eta _{0}}\cdot \mathrm{e}^{\frac{\sigma _{g}^{2}}{2\eta ...
...\sigma _{g}}\left( \frac{\sigma ^{2}_{g}}{\eta _{0}}-\eta _{0}+x\right) \right]$](img226.png) |
(5.26) |

The peak width
![]() of
of
![]() is calculated using Equations 5.17 and 5.18:
is calculated using Equations 5.17 and 5.18:
| (5.28) |
Instead of using the mean value of
![]() it is also possible to use the mean value of the gaussian part
it is also possible to use the mean value of the gaussian part
![]() of
of
![]() using Equations 5.16
and 5.18:
using Equations 5.16
and 5.18:
| (5.29) |
![\begin{displaymath}
f_{\! f\! it}\left( x\right) =\frac{A}{2\eta _{0}}\cdot \mat...
...a _{0}}+\frac{x-\overline{x_{g}}}{\sigma _{g}}\right) \right]
\end{displaymath}](img237.png) |
(5.30) |
Using the erf function instead of erfc and some transformations one obtains:
The advantage of this type of function is that values of interest
such as mean value, peak width etc. may all be directly calculated
from the fit parameters. As a further feature this type of function
allows the separation of the symmetrical from the asymmetrical part
of the fitted peak. This makes it possible to deconvolve the approximately
symmetrical contribution of the energy distribution of the primary
beam using the assumption that the energy distribution of the primary
beam is gaussian. Additionally if molecules are used as primary particles
the broadening due to dissociation can be estimated. With the definitions
used in Equation 5.22 the symmetrical part can
be rewritten as convolution of two gaussian functions:
| (5.32) |
![]() denotes the energy,
denotes the energy, ![]() the approximately
gaussian distribution of the primary energy,
the approximately
gaussian distribution of the primary energy,
![]() the combined gaussian distributed energy loss in front of the surface
and the broadening due to dissociation of molecules (see below for
a more accurate calculation).
the combined gaussian distributed energy loss in front of the surface
and the broadening due to dissociation of molecules (see below for
a more accurate calculation).
The width of the symmetrical part is then given by:
| (5.33) |
This decomposition works well for atoms as primary particles where
![]() is approximately half the value of
is approximately half the value of ![]() .
For primary molecules
.
For primary molecules
![]() dominates. In this
case the gaussian approximation might no longer be valid. A simple
model for the broadening due to dissociation is presented in the next
chapter but it is clear that these simple calculations have their
limitations.
dominates. In this
case the gaussian approximation might no longer be valid. A simple
model for the broadening due to dissociation is presented in the next
chapter but it is clear that these simple calculations have their
limitations.
March 2001 - Martin Wieser, Physikalisches Institut, University of Berne, Switzerland
![\begin{displaymath}
y(x)=\frac{A_{0}}{2A_{3}}\cdot \mathrm{e}^{\frac{A_{2}^{2}}{...
...c{A_{1}-x}{A_{2}}-\frac{A_{2}}{A_{3}}\right) \right] \right\}
\end{displaymath}](img185.png)
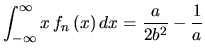
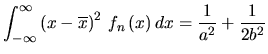
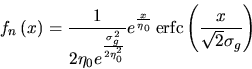
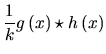
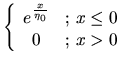
![$\displaystyle =\frac{A}{2\eta _{0}}\cdot \mathrm{e}^{\frac{\sigma _{g}^{2}}{2\e...
...\sigma ^{2}_{g}}{\eta _{0}}-\eta _{0}+x-\overline{x_{\! f\! it}}\right) \right]$](img230.png)
![\begin{displaymath}
f_{\! f\! it}\left( x\right) =\frac{A}{2\eta _{0}}\cdot \mat...
...a _{g}}-\frac{\sigma _{g}}{\eta _{0}}\right) \right] \right\}
\end{displaymath}](img238.png)